stream
stream 是什么,stream 模型
其他语言的 stream 貌似没分什么 readstream,writestream,先理解下模型吧.
假设水龙头通过水管给洒水车供水,那么这个水龙头就是提供者,洒水车就是消费者,这个小水管就是连接两者的 stream,类似,一堆数据,就是数据提供者,而我们的程序需要从某些地方获取数据,就是数据消费者 consumer,这个读取数据的通道就是 stream…
所谓读写,是站在程序的角度来说:
- 我程序需要数据,要读取,那个 stream 就是 ReadStream
像process.stdin就是要从其他地方读取数据 - 我程序要输出数据,stream 就是 WriteStream
像process.stdout/process.stderr输出数据,默认输出到 console 窗口
readable stream
1 | var Stream = require("stream"); |
- data 事件,
emit("data",data),使用on("data",handler)来接受数据 - end 事件,表示数据发送完了,
emit('end'); - close 事件,stream 关闭,
emit('close'); - error 事件,表示发生错误,
emit('error',new Error('xxxx')
使用pause()/resume()来暂停/恢复
Writable stream
1 | var ws = new Stream(); |
write() 写入数据
1 | boolean successed = ws.write(new Buffer("ABCD"),callback) |
返回 succeed 表示是否成功写入
end(可选数据) 完成发送
1 | ws.end(); |
end() -> finish 事件 -> close 事件
drain 事件
如果 write 返回 false 的话,表示这个数据消费者处理不了那么多的数据,所以没 write 成功,但当可以处理的时候,触发 drain 事件,程序可以监听这个事件,以继续 write 数据
pipe
pipe 管道的意思,链接两个 stream,
src.pipe(dest) 返回这个 dest
其中 src 必须是 readable stream,dest 必须是 writable stream
出现a.pipe(b).pipe(c)这种没有打破 src 必须为 readable stream,原因是还有可读可写 stream,学名 Duplex Stream
a.js :
1 | setInterval(function() { |
b.js :
1 | var sum = 0; |
执行
1 | > node a | node b |
结果
1 | rec : 68,sum : 0,sum+=rec : 68 |
程序 a 产生的随机数,使用 console.log 输出到程序 a 的 process.stdout 但 pipe 到了程序 b 的 process.stdin,就是类似效果
FileStream
假设要读取一个文件,并打印在控制台上,传统做法
1 | fs.readFile(__dirname + "/foo.txt", function(error, data) { |
这样做可以实现,但是当文件很大时,就会吃掉内存,而且要等待它一点一点读取完,像 Server 如果服务静态文件的话,这么做就太浪费内存,而且耗时…更好的做法是使用流的 pipe 函数:
1 | var rs = fs.createReadStream("foo.txt"); |
server 端就是 rs.pipe(response); 直接发送文件,Nginx 的 SendFile 貌似就是这样的原理
这样程序本身不用缓存
fs.createReadStream
1 | var rs = fs.createReadStream(path, option); |
返回的 rs 就是 ReadStream 类型的,可以往任意 WriteStream 里 pipe…
事件&方法
data/end/close 事件 根普通 readable stream 一致
open 事件是文件被打开的时候出发,回调参数为 fd :file descriptor
option 参数
| 字段 | 说明 |
|---|---|
| fd | 已经存在的 filedescriptor,那么 path 应该传 null |
| encoding | 编码 |
| autoClose | 默认 true,读取完是否自动关闭, |
| flags | 默认”r”,根 fs.open 那里一致 |
| mode | 默认 0666,跟 fs.open 那里一致 |
| start | 从文件哪个位置开始读取 |
| end | 读到文件哪个位置算结束 |
fs.createWriteStream
1 | var ws = fs.createWriteStream(path, option); |
有了 ReadStream 和 WriteStream,我们复制文件就方便多了…
一般小文件也就 fs.readFile 和 fs.writeFile 组合
fs-extra 库的 copySync 方法使用 fs.read 方法,规定了 64*1024 大小的 Buffer,异步的话使用 pipe 简单到家了…
1 | var fs = require("fs"); |
字段&事件
open 事件,文件打开时
bytesWritten 表示已经写入的字节数
option 参数
| 字段 | 说明 |
|---|---|
| fd | file descriptor,设置这个就设置 path = null 吧 |
| flags | 默认 w,即不存在创建;存在清空 |
| mode | 默认 0666 |
| encoding | 编码 |
| start | 从哪里开始写 |
zlib 中的 stream
可以创建 stream 的方法
1 | > zlib.create |
将 read_strem 先 pipe 至 压缩或解压缩 的 stream 中,再 pipe 至文件 WriteStream 中,压缩完成
1 | var fs = require("fs"); |
Buffer 相关
一字节包含 8 位,2 位 16 进制数,看到的 Buffer 都是两位数分开,一个字节
字节顺序
os.endianness()获取
1 | > os.endianness() |
有大字节顺序(big endianness = BE)讲的就是低位存储在高地址上
小字节(littlle endianness = LE),是低位存储在低地址上
例如 32 为的 int 值 1,占用 4 字节
00 00 00 01,01 所占位置不同,区分,下图 0x00000000 0xFFFFFFFF 即内存地址
BE 的情况是,01 出现的地址是内存地址最大的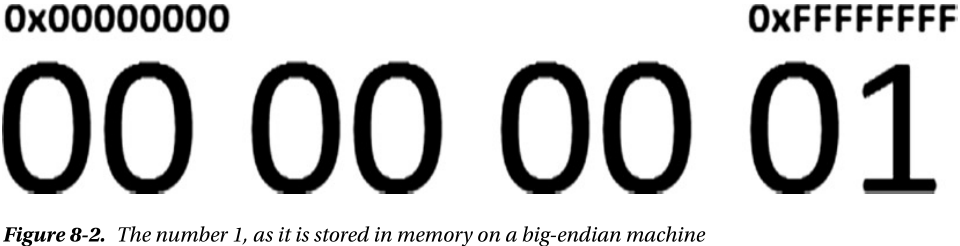
LE 的情况是,01 出现的地址是最小的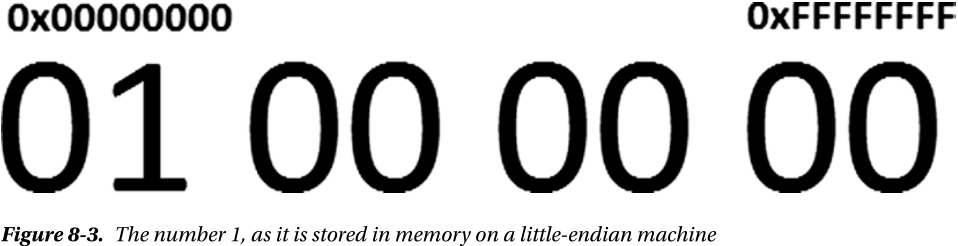
之所以说这个,是因为 Buffer 里面的 write 方法有 BE LE 后缀的就是这个区别
ArrayBuffer
提供字节数组,使用 new ArrayBuffer(size)初始化,初始化之后不能改变,可以像数组一样赋值
1 | > ab = new ArrayBuffer(5) |
可以看到:
- 超过一个字节的容量 FF = 255 时,会被截断,1000 = 3E8 截成 E8 = 232
- byteLength 表示字节个数
- slice 方法生成新的 ArrayBuffer
Buffer
构造函数
- new Buffer(1024) 数值表示大小,得到的 Buffer 是 1024 字节,也就是 1KB,值未初始化,可以用 fill(0)实例方法填充 0
- new Buffer([1,2,3]) ,用数组初始化
- new Buffer(str,encoding = “utf8”)
方法
小写 buffer 表示 Buffer 实例,大写 Buffer 表示类
buffertoString(encoding,start,end)
encoding 编码
start/end 表示截取该 buffer,来 toString
三个参数全都可选Buffer.isEncoding(“utf8”)判断参数是否是 node 认识的 encoding
1 | > Buffer.isEncoding("utf8") |
Buffer.isBuffer(buf)
正如其名Buffer.byteLength() = buffer.length
1 | new Buffer("哈哈") |
中文 utf8 宽字节,每个字 3 个字节
- buffer.fill(0)填充 0
- buffer.slice
1 | var buf1 = new Buffer(4); |
- buffer.concat([buf1,buf2])
注意参数,Buffer.concat(list,[length]),
length 是拼接后的长度,如果拼接后大于这个长度则报错
用法
1 | var buf1 = new Buffer([1, 2]); |
length 示例,给的
length=1,因为拼接后有 6 字节,报错
length=10,后面再分配 4 个字节,留用,也是未初始化状态
1 | > b |
- buffer.copy(dest, … offset …)
呢吗,参数真难记,直接用 slice 吧
- buffer.write()
参数 1 : 要写入的 string
参数 2 : buffer 的 offset,表示从哪里开始写,默认 0
参数 3 : 要写的字节数,默认全部
参数 4 : encoding
写入数值/读取数值
LE BE 就是那个字节顺序,我的 win7 是 LE,低位在小内存地址处